fravia @ Paris
Ecole polytechnique, 6 February 2001
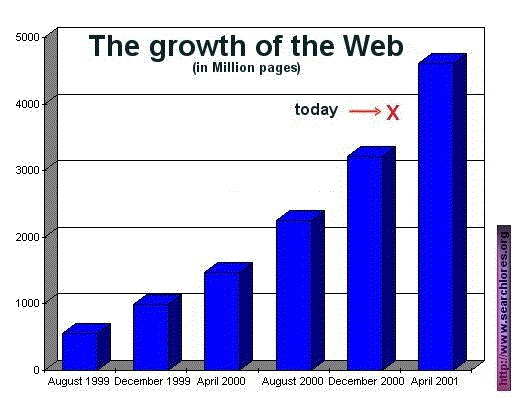
How to search: The structure of the web -why should you care?
Out there, on the web, somewhere: different laws, alien approaches, original methods, unique tactics, new solutions, proposals you would never have thought of in order to solve your local (& probably provincial) problem.