| portal → classroom → deepweb_searching.htm | ||
searching This file dwells at http://www.searchlores.org/deepweb_searching.htm |
 |
Fravia's First published in January 2008 Version 0.25, updated: 12/Feb/2008 This section supersedes the older, and now obsolete, "Special Databases" section |
How to access and exploit the shallow deep web
by fravia+
Introduction (de rerum profundae telae)
Is the "deep" web still so invisible? •• "Bad" and "good" databases
Quality on the "shallow" deep web •• "Deep web searching" strategies and techniques
Estote parati & anonymity matters •• Wget, scapy and other wonder tools
Be wary of he who would deny you access to information, for in his heart he dreams himself your master. |
"Deep web"(1) searching seems to be all the rage since a couple of years, mainly because of the supposed "undetectability" of this part of Internet by the main search engines. This was -and still often is- indeed true, probably because of a vast quantity of "proprietary databases" that did not, and do not, want their content to be indexed. These commercial ventures have always used a broad choice of "on the fly" server tricks and streaming techniques in order to further restrict the indexing capabilities of almost all bots and search engines.
Not that the main search engines' "indexing capabilities" were worth deserving much praise to start with: in fact -and this is a real problem, for seekers(2)- the most used search engines(3) have unfortunately an "indexed web-content" that: a) is quite americanocentric skewed; b) offers often obsolete results due to said s.e. own algos priorities; c) gets heavily and actively spammed by the SEO_Beasts; and moreover, d) leans anyway quite heavily towards all those useless "popularity" sites that the unwashed love and/or towards commercial sites whose purpose lies only in selling commercial trash to the unwashed themselves.
No-one knows how big the "deep web" might be, for the simple reason that noone knows how big the web "lato senso" is.
The most commonly (and uncritically) cited study(4) pretends a 550 to 1 (sic!) relation between "unindexed deep web" and "indexed web" documents. This was probably an exaggeration from the beginning, and is surely not true nowadays.
This paper profess that the many "open access" indexable databases that have recently flourished on what was the "unindexed web", have already dented the supposed huge dimensions of the ancient "deep web", both if we intend this concept, as we probably should, as "the not always indexed, but potentially indexable, web of speciality databases with specialistic knowledge" and/or if we intend the deep web strictu senso as "unindexed web", i.e. the web of "proprietary databases" plus the web "that cannot currently be indexed".
This said, a correct use of ad hoc searching techniques -as we will see- might help fellow seekers to overcome such indexing limitations for the shrinking, but still alive and kicking, "pay per view" proprietary databases.
After all winnowing out commercial trash has always been a sine qua non for searchers browsing the web: everyone for instance knows how adding even the simplistic and rather banal -".com" parameter ameliorates any query's result :-)
The problem of the deep web was very simple: many a database (and many a commercial venture) choose the obsolete "proprietary" business model and decided to restrict knowledge flows in order to scrap commercial gains. Even some "universities" (if institutes that make such choices still deserve such name) have often rakishly betrayed their original knowledge spreading mission.
This paper's apparent oxymoron about the "shallow deep web" reflects the fact that this dire situation is nowadays slowly ameliorating thank to the many worthy "open access" initiatives. The deep web of once is shallowing out, getting more and more indexed. The critical mass already reached by the open access databases harbingers a well deserved doom for the "proprietary knowledge" model of the ancient deep web.
While this text will nevertheless examine some ad hoc "deep web" searching approaches, it is opportune to recall that -anywhere on the web- some longterm web-searching techniques might require some consideration as well, while for quick queries other, different kinds of shorterm tips and advice, could also result useful.
On the other hand, some of the ad hoc deep web searching techniques explained in the following could probably come handy for many queries on the indexed part of the web as well.
Note also that this text, for examples and feedback purposes, will concentrate mainly on a specific subset of the deep web databases: academic scientific journals, since out there a huge quantity of specialised databases and repositories list everything that can be digitized, from images to music, from books to films, from government files to statistics, from personal, private data, to dangerous exploits.
The databases of the deep web have been subdivided into various groups(5): word-oriented, number-oriented, images and video, audio, electronic services and software oriented. For our "academic" search examples, we will aim mainly to word-oriented databases, (libraries, journals and academic texts): after all they are thought to represent around 70% of all databases.
This said, the real bulk of the "huge deep invisible web" consists mainly of raw data: pictures of galaxies and stars, satellite images of the earth, dna structures, molecular chemical combinations and so on. Such data might be indexed or not, but for searchers clearly represents stuff of minor interest compared with the scholar treasure troves that some specialised "academic" databases might offer(6).

It's worth keeping in mind that the "deep", "invisible", "unindexed" web is nowadays indeed getting more and more indexed.
Panta rhei, as Heraclitus is supposed to have stated: "tout changes": indeed the main search engines are now indexing parts of the "deep web" strictu senso: for instance non-HTML pages formats (pdf, word, excel, etc.) are now currently translated into HTML and therefore do appear inside the SERPs. The same holds now true for dynamic pages generated by applications like CGI or ASP database (id est: software à la Cold Fusion and Active Server Pages), that can be indexed by search engines' crawlers as long as there exist a stable URL somewhere. Ditto for all those script pages containing a "?" inside their URLs.
As an example, the mod_oai Apache module, that uses the Open Archives Initiative Protocol for Metadata Harvesting, allows search engines' crawlers (and also all assorted bots that fellow searchers might decide to use) to discover new, modified and/or deleted web resources from many a server.
Some useful indexing "light" is now therefore being thrown onto that dark and invisible deep web of once.
Web global search engines have nowadays evolved into direct -and successful- concurrents of library catalogues, even if many librarians do not seem to have noticed. What's even more important: various large "old" library databases have been fully translated into HTML pages in order to be indexed by the main web search engines.
Note that, according to the vox populi all the main search engines' indexes together (which do not overlap that much among them, btw) just cover (at best) less than 1/5 of the total probable content of the web at large, and thus miss great part of the deep web's content.
In fact most proprietary databases (and many openly accessible ones) still carry complex forms, or assorted java-script and flash scripts -and sometime even simple cookies- that can and do affect what content (if any content at all) can be gathered by the search engines' crawlers.
As seekers that use bots well know, some nasty scripts can even trap the visiting bots, and the search engines' spiders and crawlers, and send them into infinite loops, or worse.
These indexing difficulties surely persists even today. Yet, as this text will show, the deep web landscape is clearly undergoing deep changes, and the "deep", unindexed, proprietary and closed web is shallowing out in a very positive sense :-)
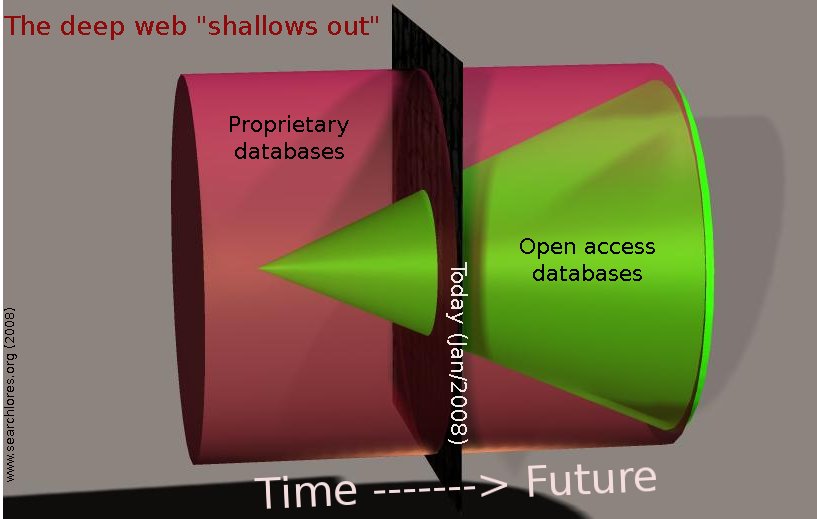
Scripts tricks are only a tiny part of the indexing difficulties that search engines encounter on the deep web: it is worth underlining that great part of the deep web is "invisible" only because of copyright obsession and excessive privatisation of common knowledge: billions of law-related articles are for instance there, but must be BOUGHT through Lexis/Nexis, billions of other articles are indexed inside a huge quantity of privately licensed databases that "sell" the right to access such knowledge.
Among the most important "bad" databases: Add to these the zillions of licensed article, magazines, references, archives, and other research resources reserved elsewhere to searchers "authorized" to use them and you'll have indeed a lot of "dark commercial matter" on the deep web. Note that the fact that the content of these databases is NOT freely available defies all economic logic: libraries, governments and corporations have to buy the rights to view such contents for their "authorized users" and visitors can mostly search, but not view such content.
This classical nasty and malignant "commercial tumor", that on the deep web was allowed to spread for years, is now -fortunately- in retreat, thank to the recent growth of the "Open Access" databases.
Before starting any search it is always worth spending some time looking for databases in the fields or topics of study or research that are of interest to you. There are real gems on the unindexed web, where -fortunately- not all databases are locked and enslaved. Nowadays searchers will often be able to gather, next to the list of "closed" interesting proprietary databases, another list of openly accessible useful databases and resources.
If you are interested in, say, history, you are nowadays for instance simply "not allowed" to ignore the existence of open repositories of databases like EuroDocs: Online Sources for European History Selected Transcriptions, Facsimiles and Translations. I mean, as a medieval buff, I wish myself I could have had something like this 30 years ago, during my Frühmittelalterliche studies :-)
Sadly, however, in this silly society of ours "proprietary" information has not always been made freely available to humankind.
Thus on the deep web strictu senso users will often be prompted to pay for knowledge that should obviously be (and of course will be in the future) freely available.
Why such services should still be left to rot in the hand of commercial profiteers with almost prehistoric business models, instead of being developed, ameliorated and offered for free to anyone by some association of universities or by some international institution, defies comprehension and any sound macroeconomic logic.
As we will see, searchers might however use some creative (if at times slightly dubious) approaches in order to access such proprietary databases "from behind", provided this is not forbidden by the legislation of their respective countries of residence or of the countries of their proxies.
Luckily, while the deep web strictu senso is still infested by proprietary databases, some nice counter-tendencies are already snowballing down the web-hills: there is in fact an emerging, and powerful, movement towards open access to research information(7).
The following examples regard mostly repositories of journals databases and newspapers' archives, but the same developments can be observed in all other specialistic fields (for instance for music: http://www.jamendo.com/en/).
-
The Front (computer science, Math,
Physics)
Has now (finally!) an "experimental" full test search, for instance deep web. -
the Directory of Open Access Journals
(for instance: "deep web" OR "invisible web").
and the OpenDOAR (Directory of Open Access Repositories)
For instance: invisible web. - Biomed central and Public library of science (Plos) (biology, medicine and genetics). Both are dedicated to Open Access. As they state: "Everything we publish is freely available online for you to read, download, copy, distribute, and use (with attribution) any way you wish".
There are COMPLETE newspapers and magazine archives searchable for free (for instance the Guardian's).
Curiously enough, it is not easy to find listings of such "open access archives". Therefore -as a proof of concept- such a list was produced in proprio :-)
It is worth pointing out that great parts of the deep web (intended both lato and strictu senso) can be accessed for academic research purposes through some well known (and quite useful) ad hoc search engines, repositories, directories and databases:
- Google scholar
For instance "deep web" - Scirus, mainly "visible" web, but some dark matter as well.
For instance invisible web - Librarians' Index
(very useful directory: for instance invisible web) - AcademicInfo
- Vascoda, german
"internet portal for scientific information", created by the
Bundesministerium für Bildung und Forschung (BMBF) and the
Deutschen Forschungsgemeinschaft (DFG).
For instance: "deep web" - Infomine (try for instance a search for "deep web" in the advanced infomine search mask, that supports also the boolean NEAR: you might usefully chose from near1 to near20)
- The internet public library (with its useful Pathfinders option!)
- Yahoo's creative commons search
For instance "deep web" - Base, "Bielefeld Academic Search Engine": Multi-disciplinary search engine
for scientifically relevant web resources, created and developed by Bielefeld University Library. Based on FAST.
For instance: "deep web"
Advanced base search.
- incywincy, which incidentally has also a quite useful (and interesting) cache (and offers also the rather practical possibility to search for forms).
-
You could use for exploring purposes also
engines like http://findarticles.com/, which
indexes millions of magazine articles and offers free full-text articles from hundreds of publications
through its advanced search engine.
For instance: "invisible web" and "deep web". - But there is an incredible palette of specialized search engines, gosh: there's even a special "uncle sam" google for US "government and military" sites... http://www.google.com/ig/usgov
Yet, despite such promising open access developments, the still impressive dimensions of the "proprietary part" of the deep web might push some seekers to use some unorthodox retrieval techniques whenever they need to harvest and/or zap the knowledge that has been buried behind commercial locks.
Fortunately (for us! Unfortunately for the proprietary content providers) the very structure of the web was made for sharing, neither for hoarding nor for selling, so there's no real way to block for long any "subscription database" against a decided seeker that knows the basic web-protocols AND has managed to fetch some sound "angles" for his queries. He'll be honing onto his target wherever it might have been hidden.
On the web and elsewhere seekers possess an almost natural -and quite sound- visceral mistrust of hype: no searcher in his right mind would for instance readily give his private data to "hyper-hyped" sniffing social networks à la facebook.
And the"deep web" has for years represented just another example of an "hyper-hyped" web phenomenon. It is pheraphs worth pointing out how a overweening excitement for all kind of hype is eo ipso a useful negative evaluation parameter.
The resources of the deep web are generally claimed to be of better quality and relevance than those offered by the indexed web, since in a ideal world they should have been written or validated by expert scholars and authorities in their particular area of expertise.
Yet, as anyone that visits the proprietary deep web can notice, many supposed "authoritative" and "knowledge rich" proprietary databases encompass, often enough, capriciously incomplete collections, full of banal truths, repetitive and pleonastic texts, obsolete and partisan positions and unfounded, unvalidated and at times rather unscientific theories. More generally, thank to the open access databases and repositories, the "academic" scientific content of the invisible web and its resources are nowadays not much "deeper" than what a researcher can find -for free- on the indexed (or indexable) web.
This resources's incompleteness is not a fault of the deep web by itself, its just due to the fact that we are still in a transition period, where the forces of old still brake the free flow of knowledge and only a relatively limited part of the content of the deep web of once is already indexed and thus really available for global open peer review on the broadest scale, review which represents the only real possible, and necessary, quality guarantee.
The situation will be brighter as soon as the full content of the deep web's proprietary databases will be finally opened and indexed in toto, maybe by new search engines that will be hopefully more competitive (and less spam-prone) than the ones most used(8) today.
Moreover, given the amazing rate of growth of the open access databases, the proprietary databases will have to open more and more their content to the search engines' indexing spiders, or risk sinking into irrelevance.
The great epocal battle for knowledge will be won when anyone, wherever he might be, and whatever economic resources he might have, will have the possibility of accessing at once and for free ANY book or text (or image, or music, or film, or poem) produced by the human race during his whole history in any language.
This is a dream that the web could already now fullfill, and this is the dream unfolding right now before our eyes.
Another interesting point is that the old quality distinction between "authorities" & "experts" on one side and "dedicated individuals" on the other is nowadays slowly disappearing. We could even state -paradoxically and taking account of all due exceptions- that those that study and publish their take on a given matter for money and career purposes (most of those deep web "authoritative experts" and almost all the young sycophants from minor and/or unknown universities that hover around many proprietary databases) will seldom be able to match the knowledge depth (and width) offered by those that work on a given argument out of sheer love and passion. If, as it is true, more and more scholarly content is nowadays provided exclusively on the web, this is also -and in considerable part- due to the "scholarly level" contributions of an army of "non academic" specialists. Electronic printing differs from traditional printing, duh.
Of course seekers will have to carefully evaluate what they have found, whomever might have written it: the old saying caveat emptor (and/or caveat fur in some cases :-) should always rule our queries.
Yet he is in for a rude surprise whomever really believes that -say- a university assistant who has worked at best a couple of years on a given matter and who simply HAS to publish his trash in order to survive and prosper economically could really offer more quality knowledge than a "dilettante" specialist who has dedicated his whole life to his "thematic passion", out of sheer interest and love.
Alas, academical publications have always been infested by wannabee experts whose only interesting dowry is to be found in the extraordinary amount of battological and homological repetitions you'll discover reading their writings.
The content of the invisible and unindexed deep web is often as poor as the content of the indexed "outside" web, and maybe even more deceiving, given its aura of supposed "deep" trustworthiness. For this reason the nuggets and jewels indeed lurking inside many deep web's databases need to be dug out cum grano salis, i.e., again, using the same sound evaluation techniques that searchers should always use, whenever and wherever they perform their queries.
The use of some of the deep web searching strategies and techniques listed in the following may result illegal in your country, so apply them only if you are sure that you are allowed to, or change country.
Let's state the obvious: deep web searching is a two-steps process: first you have to locate the target database(s), then you have to search within said database(s). However for many fellow searchers without sufficient resources, a further additional step, once found the target database on the "proprietary web", is how to enter it "from behind".
Readers might learn elsewhere the fine art of breaking into servers, here it will suffice to recall that on the web all pages and texts, be they static or dynamically created, must have an URL. Such an URL may appear complex or encrypted, but it's still just an URL.
Again: most "bad" databases have a single sign-on system: once validated, a browser session cookie with a four/six/eight hours lifetime will be stored inside the user's browser. If the user then goes to another "bad database" protected resource, the cookie will be just checked and the user is not required to type in his username and password again. Therefore you can EITHER find the correct username/password combo, OR mimick a correct cookie, which is something that seekers can easily sniff and, if needs be, recreate, using the proper tools
It's as simple as the nomen est omen old truth. It is also worth pointing out that there's no real necessity to enter a database using its official entrance gates, as this old searching essay (about the Louvre) demonstrated long ago.
Moreover, when really necessary, a searcher might decide to use some artillery in order to open closed web-doors.
Lighter techniques like guessing and luring (social engineering) or heavier approaches like password breaking, database exploiting, and/or using free VPN servers (Virtual Private Networks, which have two protocols you can manipulate: both PPTP and IPSec) can help seekers to find an entrance whenever simpler approaches should fail :-)
Since, as strange as this might and should appear, there is still no reliable collection of the largest and most important deep web databases, it is worth using for broad databases investigations the amazing locating and harvesting power offered by various ad hoc tools like wget or scapy.
A list of the existing dubious and legal approaches follows.
The most obvious approach in order to gain access to the deep web proprietary databases, has always been to use unprotected proxy servers(9) located on the campus networks of legit participating institutions.
Once found but just one working "campus proxy", a searchers can download whatever to his heart content, provided of course that such an activity is not forbidden by the laws of his country of residence, or by the laws of the country -or countries- whose proxy he uses and chains to his "target campus" proxy.
Taking some anonymity precautions would probably be a good idea for those that decide to follow this approach.
It might be politically incorrect to underline this once more, but anyone might try to access those deep web databases "from behind", without breaking any law, if he happens to live in a country (or intends to use some proxy servers from a country) which has no copyright laws at all, i.e. does not adhere to the (infamous) Berne, UCC, TRIPS and WCT patent conventions we daily suffer in euramerica.
It is maybe useful recalling here that the following countries do not adhere to any patent convention: Eritrea (ER), Kiribati (KI), Nauru (NR), Palau (PW), Somalia (SO), San Marino (SM), Turkmenistan (TM), Tuvalu (TV!) this holds even more true, of course, for all servers situated in various "difficult to control" places (Gaza strife, Waziristan, etc.).
In such cases, and using such proxies, a combination of guessing, password breaking techniques, and eventually luring (i.e. social engineering), stalking, trolling, combing and klebing (i.e.: finding interesting places/databases/back_entrances through referrals) can be used and deliver results that might be useful in order to get at those databases "from behind" (provided you have taken the necessary anonymity precautions, la va sans dire).
It might also be quite politically incorrect to point out that anyone might decide to access most commercial databases using a faked credit card, provided this is not explicitly forbidden in his country (or by the country of his proxy) and provided he has taken all the necessary anonymity precautions.
This text won't go into credit cards faking and credit card numbers generators(10) (that nowadays you can even easily find as on-line scripts). Suffice to say that given the poor security levels offered by those CVV numbers it's no wonder how credit cards themselves denounce that 95% of the scam they suffer is exclusively due to internet transactions.
Few people would feel sorry for them: it is just an anti-competitive oligarchy of an half dozen issuers, owned by banks that would not hesitate a minute to sell your kids or your inner organs for money, if they would reckon to get away with it.
It must be said also that in order to follow this approach one actually would not require neither a credit card generator nor a fake credit card at all: a keen eye in any airport's duty free queue will for instance quickly spot enough number/name/valid_until combinations to be able to download at ease all the databases of the deep web until the cows come home.
Come to think of it, a friendly waiter or seller working in any good restaurant or shop "à la mode" could also result quite helpful when dealing with such credit cards matters.
We were just joking: you don't really need to venture inside the "gray" legal areas listed above: often your own library may give you free access to your target (as long as libraries will be allowed to continue to exist in our patent-obsessed societies).
For instance, you can check here where to access in your own country, legally and for free, the whole content of a JSTOR "proprietary" database of papers, journals and essays.
Especially younger searchers seem to have forgotten, or never understood, the mighty power offered by a "physical" library inter alia in order to access all kind of web-content.
This is also valid a fortiori for the content of any good "mediatheque": why should a searcher waste his precious time downloading from the web compressed music, films and/or books when he can at once and for free get hold of, and copy, whatever full-fledged music/book/film he might fancy?
"Finding libraries"
If your local library does not subscribe the databases you want, you can find another library which subscribes to them, where you can go yourself, or maybe you could ask someone who goes there, lives there, or works there.
Lets take for example the LexisNexis database. As the access is usually restricted by IP (library's IP) and the library must link to a specific page in order for that authentication to be done, lets find that specific link. In order to do this, we can use the following banal query: inanchor:"on campus" lexisnexis, where we search for pages linking (hopefully) to LexisNexis using the anchor (the underlined clickable text linking to another site) "on campus" (humans are so predictable eh :-)
Now we know that the linked URLs are: www.lexisnexis.com/universe & www.lexisnexis.com/cis (because they do not have neither cache nor description text).
Using google (inanchor:"on campus" lexisnexis), we find another URL: web.lexis-nexis.com/universe.
Now is only a question of finding a library near you using Google: link:web.lexis-nexis.com/universe or link:www.lexisnexis.com/universe or link:www.lexisnexis.com/cis; or using Yahoo: link:http://web.lexis-nexis.com/universe -ajsks or link:http://www.lexisnexis.com/universe -ajsks or link:http://www.lexisnexis.com/cis -ajsks.
The 'ajsks' (or any other nonsense string) is used to stop Yahoo from redirecting to yahoo site search. Yahoo is even better than google for this kind of queries, because you can do more than link search (contrary to Google), you can for instance search just the libraries in France: link:http://web.lexis-nexis.com/universe domain:fr (or,of course, in any other contry).
Extracting data behind web-forms is a science per se, and there is a vaste literature on such matters(11). Many deep web forms might lead to more "specialized" second tier forms, and the obvious problem, for seekers, is to create (or find!) a client side script or bot capable to handle deep web forms with minimal human interaction.
Note that many javascripts might alter the behaviour of a form on the fly, which is a major problem for automation purposes.
Keep in mind, however, that web servers are far from behaving perfectly. Sometimes they will not respond and at times they will not send the content you expect. So if you are striving for reliability, you always need to verify that the HTTP transaction worked AND that the HTML text returned is (more or less) what you were expecting.
Some special "deep web search engines" can cut some mustard as well, for instance the already listed incywincy, which has an useful "search for forms" option.
To extract metadata a searcher could also use the GNU libextractor, that support a lot of file formats. Another possibility is wvware (that is currently useed by Abiword as Msword importer), that can access those infamous *.doc version control information data. So this is the tool for those interested in finding on the invisible web "invisible" information still hidden within the published documents, (different spelling or dates, slight reformatting or rewording, but often enough even previous different versions of the same text and very interesting corrections).
~S~ Nemo gave another intersting example! Have a look at the tricks explained for the former HotBot,that can be adapted and used through Yahoo.
Usually there's a direct correlation "celebrity" ==> "frequency" ==> ease of retrieval: the more "famous" a text, the more easy it will be to find it. E.g. the "Lord of the ring": "Gollum squealed * squirmed * clutched at Frodo * they came to bind his eyes" -babe. Notice the -babe anti-spam filter, since on the web the whole text of "famous" books is used for spamming purposes -interpolated with commercial garbage- by the beastly SEOs.
It's all nice and dandy for any famous English text, what about other languages and less known texts?
A search for -say- the french version of a japanese Haiku might take a little longer, yet even this target will be somewhere on the web, of course.
So how do we apply this "snippet" search-approach to the deep web "proprietary problems"?
Well, first we seek our target through JSTOR, for instance: The Musical Quarterly, that as we can see, http://www.jstor.org/journals/00274631.html, has a JSTOR "fixed wall" archive limit to the year 2000.
Then we completely ignore JSTOR and we seek The Musical Quarterly by itself: http://mq.oxfordjournals.org/archive/ and then we search our target there.
Now we seek an abstract or a snippet of our target: http://mq.oxfordjournals.org/content/vol88/issue1/index.dtl
Now we can find the snippet "..." (
Incidentally, even a simple tool like EtherApe, makes easy to see how a target might encompass various IPs.
For instance in this case, accessing the JSTOR portal, contact was made with two different servers: 192.84.80.37 (Manchester university, UK) and 204.153.51.41 (Princeton University, States): this kind of info comes handy when trying to find a campus proxy.
Here another simple, image-related, "guessing" example:
Visit the useful & relatively open "deep web" Art & images database at http://www.paletaworld.org/
Try its advanced search form. Let's for instance try Theme="War and battles" and country = "Greece" (leave "all countries" for the location of the paintings)
Select -say- Konstantinos Volanakis' Warship, at the bottom of the result page.
And the 1833_1.jpg image will pop up in a javascript window without URL (javascript:Popup(1833).
Now you could either check its real address using a tool à la wireshark, or simply guess it: since the name of the image is 1833_1.jpg we'll just need to find out the subfolder. You can bet it will be something like "images" or "pics" or "dbimages", or "dbpics". And indeed, lo and behold: http://www.paletaworld.org/dbimages/1833_1.jpg.
{kind=link}
(
When accessing scholastic journals the best approach, however, is to ignore as much as possible the proprietary commercial schemes concocted by the patents' afecionados and access instead "good databases" (and repositories) like the ones listed above.
As an example, the Directory of Open Access Journals (DOAJ) alone, a collection of full text, quality controlled scientific and scholarly journals that aims to cover all subjects and languages had -as of January 2008- 3073 journals in the directory, with 996 journals searchable at article level and a total of 168592 full text open articles.
The following "general" advice regard all kind of activities on the web, and is not limited to, though being very relevant for, deep web database perusing (especially when dealing with proprietary "pay per view" databases).
Estote parati
The browser, your sword
Do yourself a --huge-- favour and use a really powerful and quick browser like Opera.
Besides its many anti-advertisement and quick note-taking bonuses, its incredible speed is simply invaluable for time-pressed seekers.
You can of course rig firefox, hammering inside it a quantity of adds-on and extensions, in order to get it working almost as well as Opera does out of the box, yet firefox will still be much slower than Opera.
For your text data mining purposes, consider also using ultra-quick (and powerful) CLI-browsers à la elinks instead of the slower GUI browsers: you don't really need all those useless images and awful ads when data mining gathering books and essays, do you?
The operating system, your shield
You MUST choose a good operating system like GNU/Linux: for serious web-searching purposes you cannot and should not use toy operating systems like windows, it would be like walking blindfolded on a web of mines: much too slow, no anonymity whatsoever and quite prone to dangerous (and potentially serious) viral/rootkits problems.
Use the powerful and clean Ubuntu (debian) distribution, or try one of the various "wardriving oriented" GNU/Linux versions, e.g.: Wifislax or Backtrack, that you'll then either just boot live onto your Ubuntu box (as an added anonymity layer, see below) or simply install in extenso, instead of Ubuntu.
A good approach is to create from the beginning a false -but credible- complete identity, so no "John Smith", no "Captain Spock" and no "Superterminator": open the phone book instead, and chose a Name, a Surname and an address from three different pages. Create "his" email on -say- yahoo or gmail, but also on a more esoteric and less known free email provider, that you'll use whenever some form-clown will ask for a "non-yahoo" email-address.
You'll also need a relatively "anonymous" laptop for your wardriving purposes, hence, if possible, bought cash (no credit cards' track) in another country/town, a laptop that you will henceforth connect to the web ONLY for wardriving purposes.
Your settings on your laptop (in fact, on all your boxes) should always result as "banal" (and hence as anonymous) as possible, either respecting your bogus identity: Laura@mypc if your chosen fake first name was "Laura", or just combinations that might at least rise some confusion: cron@provider; probingbot@shell, grandma@pension_laptop, etc.
Once on line, always watch your steps and never never never smear your real data around.
When using your "dedicated" laptop you should only wardrive, browse and download: NO private posting/uploading personal stuff/emailing friends/messageboard interactions/IRC chatting... NEVER.
Keep an updated list of the quickest wi-fi connections you'll have found through wardriving: location and speed.
Choose preferably places with a bunch of quick connections that you can reach in a relatively unobtrusive manner, for instance sitting quietly inside some brasserie or cafe.
Always choose WEP "protected" access points if you can (WEP "protection" is a joke that any kid can crack in 5 minutes flat): such "WEP protected" access points tend (in general) to be much quicker than any totally open and unprotected access point.
Have a good list of quick proxies at hand. Some of the "unconventioned" nations listed above offer interesting everlasting proxies, that seem rather unbothered by the euramerican copyrights and patents lobbing mobs.
Use regularly a MACchanger for your laptop in order to change systematically (but randomly) its wifi MAC signature.
You'r now all set for your relative anonymity, and you are ready to visit (and enter) any database, using whatever means might work, even the "dubious" approaches described above, if you deem it necessary.
Consider that even observing all possible precautionary measures, if someone with enough resources and power really wants to snatch you, he probably will: when entering the gray areas of the web, being a tag paranoid is probably a good idea.
Just in case, change often your access points and -of course- alter irregularly, but systematically, your preferred wardriving locations and your timing & browsing patterns.
Unwashed should begin playing with each one of them for at least a couple of days, gasping in awe.
Wget
Network traffic is displayed graphically. The more "talkative" a node is, the bigger its representation. Most useful "quick checker" when you browse around.
- Node and link color shows the most used protocol.
- User may select what level of the protocol stack to concentrate on.
- You may either look at traffic within your network, end to end IP, or even port to port TCP.
- Data can be captured "off the wire" from a live network connection, or read from a tcpdump capture file.
- Live data can be read from ethernet, FDDI, PPP and SLIP interfaces.
- The following frame and packet types are currently supported: ETH_II, 802.2, 803.3, IP, IPv6, ARP, X25L3, REVARP, ATALK, AARP, IPX, VINES, TRAIN, LOOP, VLAN, ICMP, IGMP, GGP, IPIP, TCP, EGP, PUP, UDP, IDP, TP, IPV6, ROUTING, RSVP, GRE, ESP, AH, ICMPV6, EON, VINES, EIGRP, OSPF, ENCAP, PIM, IPCOMP, VRRP; and most TCP and UDP services, like TELNET, FTP, HTTP, POP3, NNTP, NETBIOS, IRC, DOMAIN, SNMP, etc.
- Data display can be refined using a network filter.
- Display averaging and node persistence times are fully configurable.
- Name resolution is done using standard libc functions, thus supporting DNS, hosts file, etc.
- Clicking on a node/link opens a detail dialog showing protocol breakdown and other traffic statistics.
- Protocol summary dialog shows global traffic statistics by protocol.
Wireshark, the world's most powerful network protocol analyzer, a sort of tcpdump on steroids, is a GNU licensed free software package that outperforms tools costing thousands of euro and has an incredible bounty of mighty features (but learn how to use its filters, or you'll sink inside your captured data):
- Deep inspection of hundreds of protocols,
- Live capture and offline analysis
- Captured network data can be browsed via a GUI, or via the TTY-mode TShark utility
- Most powerful display filters
- Rich VoIP analysis
- Read/write many different capture file formats: tcpdump (libpcap), Catapult DCT2000, Cisco Secure IDS iplog, Microsoft Network Monitor, Network General Sniffer® (compressed and uncompressed), Sniffer® Pro, and NetXray®, Network Instruments Observer, Novell LANalyzer, RADCOM WAN/LAN Analyzer, Shomiti/Finisar Surveyor, Tektronix K12xx, Visual Networks Visual UpTime, WildPackets EtherPeek/TokenPeek/AiroPeek, and many others
- Capture files compressed with gzip can be decompressed on the fly
- Live data can be read from Ethernet, IEEE 802.11, PPP/HDLC, ATM, Bluetooth, USB, Token Ring, Frame Relay, FDDI, and others (depending on your platfrom)
- Decryption support for many protocols, including IPsec, ISAKMP, Kerberos, SNMPv3, SSL/TLS, WEP, and WPA/WPA2
- Coloring rules can be applied to the packet list for quick, intuitive analysis
- Output can be exported to XML, PostScript, CSV, or plain text
This little marvel is able to forge or decode packets of a wide number of protocols, send them on the wire, capture them, match requests and replies, and much more. It can easily handle most classical tasks like scanning, tracerouting, probing, unit tests, attacks or network discovery (it can replace hping, 85% of nmap, arpspoof, arp-sk, arping, tcpdump, tethereal, p0f, etc.). It also performs very well at a lot of other specific tasks that most other tools can't handle, like sending invalid frames, injecting your own 802.11 frames, combining techniques (VLAN hopping+ARP cache poisoning, VOIP decoding on WEP encrypted channel, ...), etc :-)
(Seekers' Suggestions)
Finally there are some wondrous CLI tools that -amazingly enough- many searchers don't use: For instance the mighty useful, dutch mtr ("my traceroute": allinone traceroute+ping... and more!):
me@mybox:~$ sudo mtr www.searchlores.orgUse the "n" key to switch between DNS-names and IPs.
[+fravia]
The burp suite is a java application (so, cross platform) that functions like a one-shot proxomitron swiss army knife,
allowing you to edit any and all HTTP requests and responses as you see fit.
It also has a load of other features (some useful for searching, some for other things)
that are definitely worth getting acquainted with.
[~S~ ritz]

1) Terminology nightmares
The "Deep web" is also known as "Unindexed web" or "Invisible web", these terms being used nowadays in the literature as equivalents.
The "non deep", "indexed web" is on the other hand also known as "Shallow Web", "Surface Web" or "Static Web".
We could not resist adding further confusion to this searchscape, stating in this paper that the so-called "deep web" is in reality nowadays rather shallow (hence the "shallow deep web" oxymoron), if we calculate -as we should- depth as directly proportional to "unindexability".
The "deep web" (of old) is in fact more and more indexed (and indexable). This is due, among other things, to the mighty spreading of open access repositories and databases that follow a publishing model ("knowledge should be free for all, at last") that harbingers a well deserved doom for the "proprietary knowledge" and "pay per view" models of the now obsolete web of old: deep, invisible, proprietary and in definitive rather useless because badly indexed or impossible to index.
2) What is a seeker?
Like a skilled native, the able seeker has become part of the web. He knows the smell of his forest: the foul-smelling mud of the popups, the slime of a rotting commercial javascript. He knows the sounds of the web: the gentle rustling of the jpgs, the cries of the brightly colored mp3s that chase one another among the trees, singing as they go; the dark snuffling of the m4as, the mechanical, monotone clanking of the huge, blind databases, the pathetic cry of the common user: a plaintive cooing that slides from one useless page down to the next until it dies away in a sad, little moan. In fact, to all those who do not understand it, today's Internet looks more and more like a closed, hostile and terribly boring commercial world. Yet if you stop and hear attentively, you may be able to hear the seekers, deep into the shadows, singing a lusty chorus of praise to this wonderful world of theirs -- a world that gives them everything they want. The web is the habitat of the seeker, and in return for his knowledge and skill it satisfies all his needs.
The seeker does not even need any more to hoard on his hard disks whatever he has found: all the various images, musics, films, books and whatnot that he fetches from the web... he can just taste and leave there what he finds, without even copying it, because he knows that nothing can disappear any more: once anything lands on the web, it will always be there, available for the eternity to all those that possess its secret name...
The web-quicksand moves all the time, yet nothing can sink.
In order to fetch all kinds of delicious fruits, the seeker just needs to raise his sharp searchstrings.
In perfect harmony with the surrounding internet forest, he can fetch again and again, at will, any target he fancies, wherever it may have been "hidden". The seeker moves unseen among sites and backbones, using his anonymity skills, his powerful proxomitron shield and his mighty HOST file. If need be, he can quickly hide among the zombies, mimicking their behavior and thus disappearing into the mass.
Moving silently along the cornucopial forest of his web, picking his fruits and digging his jewels, the seeker avoids easily the many vicious traps that have been set to catch all the furry, sad little animals that happily use MSIE (and outlook), that use only one-word google "searches", and that browse and chat around all the time without proxies, bouncing against trackers and web-bugs and smearing all their personal data around.
Moreover the seeker is armed: his sharp browser will quickly cut to pieces any slimy javascript or rotting advertisement that the commercial beasts may have put on his way. His bots' jaws will tear apart any database defense, his powerful scripts will send perfectly balanced searchstrings far into the web-forest.
3) & 8) Most used search engines
Data extrapolated from nielsen, hitwise and alia.
The most used search engines are at the moment (January 2008) on planetary scale google (58%), yahoo (20%), MSNSearch (7%) and ASK (3%), with slight variants for the usage in the States (where MSNSearch covers 15% of all searches, while AOL has a 5% usage).
Note that these search engines are the most used, not the best ones (just try out exalead :-)
4) Bergman
Bergman, M.K., "The Deep Web: surfacing hidden value", Journal of Electronic Publishing, Vol. 7, No. 1, 2001. It's almost ironic to find this document inside brightplanet, which is part of the awful and next to useless "completeplanet" deep web search engine. Of course the same document is available elsewhere as well.
5) Williams
Williams, Martha E. "The State of Databases Today: 2005".
Jacqueline K. Mueckenheim (Ed.), Gale Directory of Databases, Vol. 1: Online Databases 2005, part 1 (s. xv-xxv). Detroit, MI: Thomson Gale, 2005
6) Lewandowski
See "Exploring the academic invisible web" by Dirk Lewandowski and Philipp Mayr, 2007.
7) Is 97% of the deep web publicly available?
Some researchers even arrived (many years ago) to astonishing conclusions in this respect: "One of the more counter-intuitive results is that 97.4% of deep Web sites are publicly available without restriction; a further 1.6% are mixed (limited results publicly available with greater results requiring subscription and/or paid fees); only 1.1% of results are totally subscription or fee limited (Michael K. Bergman, "white paper" in The Journal of Electronic Publishing, August 2001, Volume 7, Issue 1)"
Beats me how anyone can dare to state on such deep matters exact percentages like "97.4%", "1.6%" and/or "1.1%" without deeply blushing.
9) Proxies
We give for acquired that searchers and readers know already how to find, choose, use and chain together proxies in order to bypass censorship attempts and to probe interesting servers and databases. The main point is that a proxy does not simply pass your http request along to your target: it generates a new request for the remote information.
The target database is hence probed by a proxy in -say- Tuvalu, subjected to Tuvalu's non-existing copyright laws, while the searcher's own laptop does not access the target database, thus somehow respecting the dogmatic decrees of the commercial powers that rule us.
Still, chaining (and rotating) proxies is a fundamental precaution when accessing and probing databases along the gray corridors of the web. You can and should use ad hoc software for this purpose, but you should also know how to chain proxies per hand, simply adding a -_-, in the address field of your browser, between their respective URLs: http://www.worksurf.org/cgi-bin/nph-proxy.cgi/-_-/http://anonymouse.org/cgi-bin/anon-www.cgi/http://www.altavista.com,
(If you use numeric IP proxies, just chain them directly using a simple slash / between their URLs).
10) Credit cards faking
If you really want to delve into credit cards' security, start from Everything you ever wanted to know about CC's and from Anatomy of Credit Card Numbers.
11) Extracting forms
There is a huge literature.
See for instance "Extracting Data Behind Web Forms" by Stephen W. Liddle, David W. Embley, Del T. Scott & Sai Ho Yau, 2002.
(Statistical predictions about the data that must be submitted to forms. Dealing with forms that do not require user authentication)
Also check "Light-weight Domain-based Form Assistant: Querying Web Databases On the Fly" by Zhen Zhang, Bin He Kevin & Chen-Chuan Chang, 2005.
(Creating a "form assistant" and discussing the problem of binding costraints & mandatory templates)