Web-searching Session
@ Hal2001
(Twente, Holland ~ Saturday 11 August 2001)
Web wizard searching techniques, anti-advertisement galore
and software
reversing tips
by fravia+
with useful linguistic corrections provided by Anna, Queen of Saba and e=h
Introduction
Evaluating results
A glimpse of the web
Klebing and other non kosher techniques
The need to fight against advertisement
Eliminating advertisement banners (Opera 5.1)
Introduction
I'm happy to be here. And I would like to thank those who have invited me to
hold a
workshop to-day.
The title of this workshop is
'Web wizard searching techniques, anti-advertisement galore and software
reversing tips'
Since some among the presents will be quite web-savvy, whereas some other will not be so
confident with
the subject, I'll try to-day to find a path capable to satisfy everyone.
This is at
times difficult, so please if something appears obscure just interrupt me with
any questions
you may have and/or note down the specific lore you are interested in, we'll
delve into
it deeper on request -if time allows- at the end of this workshop.
Searching the web is of paramount importance, for reasons that are easy to
understand:
since gathering information is now both cheap and effective, society is
changing. When
gathering information was expensive it made economic sense for decisions to be
made in few central places. Now, with communication costs next to nothing, more
and more people can easily be well enough informed to act independently. This is paramount to
a revolution of considerable scale: those that learn how to find knowledge
on the web ('hidden' as well as 'open') will find eo ipso
quite some opportunities to 'move' things on the right paths... or at least to counter the decisions still
that are still being made 'in few central places' by the dark side.
The
amount of information you can now gather on the web is truly staggering.
Let's see... how many fairy tales do you think human beings have ever written
since the dawn of human culture?
How many songs has our race sung?
How many pictures have humans drawn?
How many books in how many languages have been drafted?
The mind shudders, eh?
In fact, already now, every text, every music, every software program, every
image, every book is on the web. Moreover: everything that goes on the web will
'remain' there forever, carved in copycatted electrons. It is next to
impossible to 'pull down' a text, a whole site or an image, once published.
But there are even more important goodies than media products out there. There
are SOLUTIONS! Imagine you're an administrator, or a consumer defender, or a
lawyer, or a scientist, or simply yourself when seeking a solution, doesn't
matter a solution to what, ça c'est égale.
Well, you can bet: the solution to your problem is there, somewhere.
Actually you'll probably find MORE
THAN ONE solution to your current problem, and maybe you'll be even able to
build on what you'll have found to develop another further approach.
I would also like to go beyond powerful searching techniques, if time permits, in order to
underline the cosmic power that software reverse
engineering can give you. Therefore I will close this workshop demonstrating a
simple technique to get rid of advertisement banners planted inside software
(using the latest version of the very good 'Opera' browser as example and
target). Since this approach does not require any particular software reversing
skill and can thus be applied by anyone of normal intelligence, it should help
to put a nice stop to a pestering habit that utterly annoys me: unpleasant advertisement inside
software.
When learning how to search the web one of the most important, lore is how to
evaluate the results you find.
Evaluating results
Before beginning my workshop I feel I owe you an explanation...
and at the same time I take the opportunity to introduce a most important web-seeking
lore: 'evaluation'
You may wonder - as you always should
when attending any conference whatsoever - why you should actually bother to listen to me today.
The importance of evaluating the
results of your query should never be underestimated on a web where fake rules,
and where scattered gems of knowledge must be dug
out from beneath heaps of commercial crap.
You MUST learn to evaluate -quickly and effectively- the 'authority' of any
Author on any matter or subject, without necessarily knowing thoroughly such
specific matter or subject (which, admittedly, would help you a lot in your
evaluation :-)
A simple rule of thumb is to calculate 1) how much time the subject has spent on
the matter, 2) how consistent he was in his line of investigation (you shouldn't
for instance buy a sail-ship from somebody that began assembling them a couple
of years ago after having done quite different things all his life long) and 3)
how much he is valued among his 'peers'.
Yet you should never forget that even when all the three conditions above are
satisfied you could still be easily deceived by carefully masked incompetence.
There are two more helpful parameters you should consider when evaluating a speaker:
his 'stolid stubbornness' (or load of prejudices) on the negative side and, on the
positive side, how much chances you have to verify his asserted data.
The first point: Author's prejudices, is VERY important
when evaluating. Always remember that people who
take themselves too seriously have great difficulty in changing their own minds when
proved wrong. This applies in general to whomever is commercially 'obfuscated'. In general
you should be wary to trust those whose career depends from how they are PERCEIVED,
and not from what they really know.
I'll exemplify the second point: possibility to verify asserted data,
using the 'librarian' difference between books that have footnotes
and books that have endnotes. Endnotes are more cumbersome to check, hence you
tend to have to rely more on what the Author says. Footnotes can (could) be
immediately checked, hence you can (could) discuss or question step by
step what the Author says.
So footnotes are more 'honest' than endnotes. Quite
a difference of style, if you think about it.
Fortunately nowadays with the web available to everyone, knowing how to search
for references, we can immediately check whatever anybody says on the fly.
This is the
same as if we
always had had 'footnotes'... for every text we find. De facto it means that we can have
a footnotes 'equivalent' even when dealing with Authors that would rather
hide behind endnotes (and also with whomever would rather not use any
explaining notes
at all :-)
Finally there are 'global' characteristics that unveil charlatans, on the
web and elsewhere: the Author shows
strong arrogance; extreme loquacity;
frequent appeal to emotions; repeated appeal to supreme authorities;
incomprehensible language; untarnished
conviction of his
own importance (often with the paranoid corollary of being unjustly persecuted);
and an almost absolute certainty
that who does not agree with him is either fool or vile.
Back to this workshop:
Fundamentally, you are listening to me because I have been present on the web
for what in Internet is regarded as a long time (7 years) dealing with themes
that are reciprocally intertwinned: web-searching, software reversing,
anti-advertisement and anonymity lore.
Should you wonder why these themes are intertwinned, rest assured: one of the
aims of this workshop is precisely to clear this point. Moreover I am - in my 'real' life -
both a linguist and a historian.
I can assure you that when searching the web being able to
understand 5 major languages is an asset, no less than
knowing rhetoric and sources-collation.
Finally I could point out to some advanced work that has been made on my sites -thanks
to the help and knowledge of
other powerful seekers- on matters related to searching. We have for instance introduced
this year our 'scrolls', a term that refers to some small -but powerful-
searchbots (in this case small scripts written in php) that will allow searchers to
find their useful quarries on any search engine they select, for how long as they
select and as deep as they select.
For these reasons I have
been asked by several friends and European universities to hold this kind of
workshops.
All this, of course, does not mean much. The proof, as always, will be in the
pudding. It will be up to you to evaluate this workshop after having attended
it. Your critical comments and suggestions are welcome.
I won't give - in general - many references supporting my statements. As said, among
searchers references should not be necessary. When I state -for instance- that the
'diameter' of the web is around 19 clicks, you have already enough angles
to find all necessary references by yourselves, and then some. Thus you'll be able to
'find my missing footnotes' and check or refute such a statement on your own.
That's the beauty of websearching...
reminds early medieval "Quellenforschung" techniques. Yep, you should search for that
lore as well :-)
A glimpse of the web
I cannot even conceive to begin a workshop about web searching without an
attempt to show a searcher's "vision" of the web. It is important to understand
how big Internet
is and how it looks like (from a searcher's point of view). In fact, despite its width
and complexity, a searcher will take comfort knowing that the Web 'diameter' will always remain
narrow enough to allow any one who is capable to find anything he is looking for,
irrespective of the
amazing speed, and pace, of Internet's growth.
Now, to say that you can really find anything on the web would be a lie,
but -as we will see- such a lie 'lies' less and
less far from truth.
I'm not exaggerating. Whole national libraries are going
massively on-line in some godforsaken country at this very moment. Tumbling
prices for scanners, hard disks and web-connection made this possible. In fact
every media product is most probably already on the web... somewhere, albeit
buried under huge mountains of mindless futility and commercial crap.
So, how big is the web?
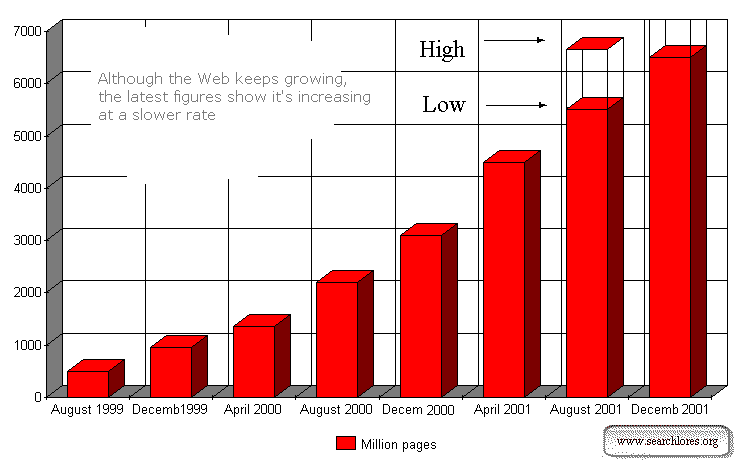
As you can see from the graphic above, the web now measures something between 5
billions (5000 millions) indexed pages and 6 billions (6000 millions) indexed
pages. Keeping in mind that the more powerful among the 'main' search engines (best non
boolean: webtop and google; best boolean: fast and hotbot) cover on their own one
fifth of this 'bulk' you'll easily realize why you'll need other means -and
strategies- in order to search the web.
The figures above, however, are just my own collation from various surveys,
surveys themselves based on tiny 'segments' of the web that have been object of
specific research from 1999 onwards. The error margin is huge and the
real figure, i.e. the real dimension of the web, is unfortunately anybody's guess.
The two main 'philosophic schools' are at the moment
1) a 'slowing down'
hypothesis -still not confirmed- that would give for august 2001 a dimension
slightly above 5000 million pages.
2) a 'keeping the pace' hypothesis
-still not confirmed- that would give for august 2001 a dimension slightly above 6000
million pages.
Anyway, as said, the diameter of the web is relatively narrow:
19 clicks. Studies have
shown that you can go from any page of the web to any other page with a maximum
of 19 clicks. Even if the dimensions of the web should further increase with the
amazing pace shown in the recent years, it is unlikely that its diameter would
ever reach a logarhitmic barrier fixed at 22 clicks.
This is, for obvious reasons, excellent news for seekers. It means, translated,
that no matter how big the web is, or will ever be, you'll be able to find your
quarry in a reasonable lapse of time... provided you know how to search, that
is.
I would be at a loss to specify what exactly such "a
reasonable lapse of time"
should be. It depends of course on the kind of target (text, image, sound,
person or event) and from the language you are searching in (English still
commands 86% of the web).
Short term searching and a Long term searching
First of all, as we will see, there are two searching strategies:
a "short term" searching and a "long term" searching. The "short" approach allows you to
search 3/4 of the web, the "long term" one will give you (almost) the whole indexable web.
Let's say that in general, as a rule of thumb, if you don't find your short term
quarry in 15 minutes, this means that your search strategy is wrong. Please note
that finding simple 'short term' targets should NOT require more than 5 minutes.
Now, I hear you asking... how exactly do you accomplish that? How do you really find
any target in few minutes?
Well, there are various approaches you may be tempted to explore, from the
simplest, like combing, i.e. fishing inside usenet's newsgroups, perusing local
messageboards, taking advantage of regional searchengines, private homepages
repositories and webrings, to the more complex paths of writing your own bots
and/or reversing commercial bots.
Each one of these techniques will allow you to gather 'angles' for a long term strategy.
Short term seeking and long term seeking are different beasts.
The various searching techniques that we will deal with in a minute will help you not
only to increase the
depth of your searches beyond the 33% that -in the best case- the main search engines
will allow you to cover if used properly and together.
The various techniques will allow you also to gather various 'angles' onto which
you will be able to base
your long term searches,
in order to 'grasp the guts' of the tantalizing
1/4 of the web that all the techniques we know of, together, will
still not cover.
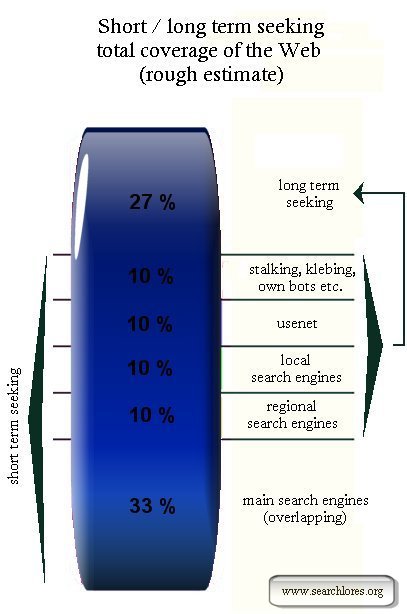
Yet, before examining the various techniques in depth, we will need
to have a look at the structure of the web, which
is of paramount importance for seekers, as you will, I'm sure, agree in a
couple of minutes.
How does the web 'look like'? From a searcher's standpoint, the web looks like
this:
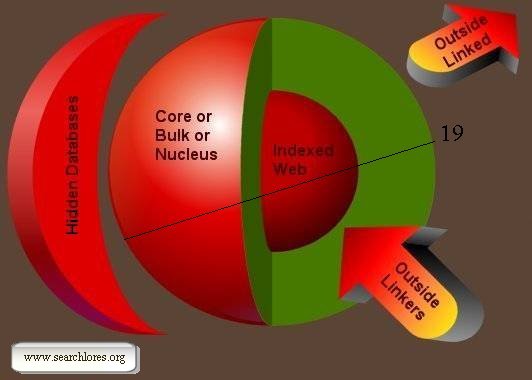
As you can see, there is a huge 'core', or 'bulk', made out of reciprocally
linked pages. This is the CORE of the web, strongly interconnected pages, sites,
Usenet newsgroups, messageboards, you name it. This is the 'web' as you know it,
where you happily browse from link to link smearing all your personal data
along, as we'll see later examining some anonymity themes.
It is not easy to represent the web in three dimensions. As a matter of fact the
Nucleus is far from being the compact and uniform 'ball' of
interconnected sites you are looking at in this image... you should think at a
fractal like entity, with almost 'organic' features, with spaghetti-similar
'tubes' that quickly connect some areas while leaving 'link-holes' in many
places. It would probably look like a huge chump of Gruyere :-)
As the image behind my shoulders should make clear, only a relatively small part
of the Nucleus has been indexed by any search engine.
In fact the main search engines' coverage of the web is extremely limited:
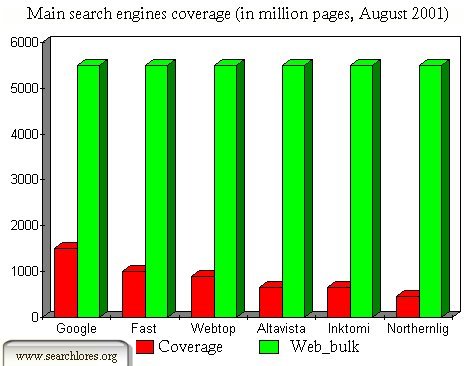
As you can see, the coverage of the bulk by the main search engines (which
-note- overlap among themselves for almost the 60-80%) is at best around 25%.
It has been calculated that with overlaps among them, the main search engines
cover at best a meager third (33%) of the web.
Take note that a significant part of the huge bulk is USENET, huge mass of
micro-information, which can frequently give quite useful results, especially for
long term seeking (and combing, klebing and stalking) purposes.
There are some specific search
engines used for usenet searching, the most famous one was for many years
the famous dejavue (deja.com), which has been now acquired by google (under the name
'groups.google.com':
http://groups.google.com/advanced_group_search).
So, back to our 'image' of the structure of the web.
For searching purposes the web is divided into parts that link
to and/or are linked from the Nucleus.
First of all there's a big area called "Outside linked". This consists of pages
and files that the Nucleus links towards, but that do NOT point reciprocally
back to the Nucleus. Thus they are 'outside' the reciprocally connected bulk,
yet they are not particularly difficult to find. In order to search this part of
the web, mostly made of non-hidden databases (imagine an observatory linking to a
huge collection of
star images, for instance) you'll use the same techniques (power-searching, combing
and building your own searchbots) commonly used in order to search the Nucleus.
Then there's another big area called "Outside linkers". The pages located in
this area of the web "point" to the Nucleus but are not pointed back from it.
Imagine as an example the "personal links" pages of a scientist: lotta "juicy"
links to the Nucleus yet no need for him to publicise their existence. There is -per
definition- NO LINK from the Nucleus that you could use in order to
browse and peruse back to this part of
the Web.
Outside linkers are often VERY important: a page with information
you may need is there, somewhere, yet without any
link whatsoever that could bring you to it.
The "outside linkers" may hoard
knowledge you need but are a part of the web you cannot reach using "normal"
search techniques, since no link whatsoever points to them.
There are, fortunately, some techniques that you can apply
in order to find them. The most common one being klebing, as we'll see in a
minute.
Then we have a big area (or to be more precise, a very big quantity of small
areas scattered around the Nucleus, but I didn't know how to draw it) of hidden
databases which are connected to the bulk, but that can be accessed (in theory)
only conditionally.
In fact these 'hidden databases' contain pages or files that the Nucleus points
to, and that may (or may not) point back to the Nucleus. Yet for commercial (or
other access-restrictive) reasons visitors of sites located here are supposed to
"pay" (or adhere to some "clan") in order to access them. As you may imagine,
these pages are NOT mutually linked (but they might point to some "outside
linkers" as well).
Fortunately (for us, unfortunately for the commercial bastards) the web was
originally built in order to share (and neither to hoard nor to sell) knowledge.
And thus the building blocks, the "basic frames" behind the structure of the web
are still helpful for whomever want to share.
If I may dare a 'crackers' comparison: exactly as it is pretty easy to break any software
protection written in a higher language if you know (and use) some assembly, so
it is easy to break any server-user delivered "barrier" to a given database if
you know (and can "outflank" and/or exploit) the protocols used by browsers and
servers.
Let's simply say that it is relatively easy to access all pages in this "hidden
databases" area of the web reversing the (simple) perl or javascript tricks used
to keep them "off limits" for zombies and lusers ("losers users"). A sound
knowledge of Internet protocols and the ability of Guessing (which can be a very
sofisticated Art) represent an incredibly powerful approach in this field.
How to search
So, now that we have examined the various areas of the web, let's begin to
discuss which search strategies you should use, and where. Note that my aim is
simply to present you a broad palette of the many possible approaches. The most
important thing you should heed is that when searching the web you should use
MANY different techniques. Of course you may start any broad query with the help
of the main search engines.
Please note the plural: search engines: a common mistake is to 'get used' to a
single main search engine, say google, and use always and only google
henceforth. In fact you should always use AT LEAST a couple of them, preferably
a non-boolean search engine (like google or webtop) and a boolean one (like
fast, hotbot or altavista).
Yet, as we have seen, the main search engines DO NOT INDEX a huge part of the
Web. Moreover the main search engines apply an active censorship to the results
that they will give you (try searching for mp3 on anyone of the main search
engines if you are not convinced).
If you limit your searches to the results offered by the main search engines you
would therefore never have a chance to grasp 'the guts' of your signal. Hence
the importance of the different searching techniques that we will now examine.
A good fundamental idea, when searching for something, is to search those who
have already searched. In fact you can be sure that, whatever your interest,
many others, somewhere and somewhen, will have already searched for it. Finding
the results of their work can 'jumpstart' your own search forward, allow you to
ride quickly on their shoulders and spare you a long tedious time searching your
signal among the noise.
This kind of approach is called 'combing'.
You may comb either for those that have already searched and are willing to
share or you may comb for both these and also those that have already searched
and are not willing to share the information and knowledge they have found.
In the first case the main approach involves usenet searching,
regional
searching and
local searching (private messageboard perusing, private homepages
repositories fishing, etcetera), in the second case you must further add less
'kosher' techniques like stalking, klebing,
hacking, guessing and luring.
It is now high time to explain some of this terminology.
Usenet searching
Usenet is EXTREMELY useful for combing purposes because:
- Many among those that employ usenet know something indeed. I'm always amazed
to perceive the wondrous depth of knowledge possessed by many people that actively post
on usenet. On the other hand I'm even more amazed when I discover that
part of my audiences didn't even know that usenet exists.
-
Many usenet messages point to useful sites (a simple URL-gathering bot that
you lash onto your selected usenet groups can quickly give you gorgeous results)
- There's no point in reinventing a wheel that not only already exist in various
forms, but will be most of then time FAR superior to the one you would have
soon or later invented if you had had the time :-)
- Note that there are special usenet services, like green egg, that
automatically gather all URLs that appeared inside usenet messages. I'm sure you
can understand how important this can be for searchers.
Regional searching
Regional searching means -in its simplest form- the use of geographically
specific search engines. Of course a search for -say- Spanish search engines
will give you different results if you search first a main search engine for
'spanish search engines' or if you rather search for 'buscadores hispanos'.
Knowledge of languages is of paramount importance when performing regional
searches. This may require some specific linguistic search on its own, but,
believe me, the gems you'll find searching in Russian or Korean search engines
for the local equivalent of 'warez' or 'gamez' will compensate you in
abundantiam for the time spent in your own linguistic fine-tuning.
FTP-fishing in foreign languages (say Chinese, Japanese, Russian, Polish) will
also enable you to find some incredible jewels.
You should always remember that there is a very small overlap between main
search engines and good (i.e. REALLY geographically specific) regional search
engines. This means that you can get through regional engines to some area of
the bulk where no main search engine ever dared to adventure.
As a 'global' starting point for regional searching, have a look at searchalot:
http://www.searchalot.com/texis/open/internationalframer
Local searching
Encompasses, among other techniques, the following:-
Private messageboard perusing
- Private homepages repositories fishing
- Public counters backtracing
- Web-rings searching
- Domain-names searching
Let's quickly examine these various 'local searching' approaches.
Private messageboard perusing
Employing this approach is useful because:
- Not everyone makes use of usenet. Public and private messageboards abound on
the web. You may find them trough the main and regional (and local) search
engines or you may find them combing usenet (see above) or you may find them
trough referral backtracing from your own loggings (klebing).
- Some of these private messageboards are extremely active and are indeed
visited by world-level experts.
- People that have searched and are not willing to share the knowledge DO lurk
actively on private messageboards, often disguising as newbies when seeking
specific information. Simple stalking and luring techniques may come quite handy
in these cases :-)
La va sans dire that in general you should not waste your own time perusing huge
constellations of small messageboards. Ad hoc bots will allow you to grep (i.e automatically
gather, collect and collate)
quickly and regularly whatever you are looking for. For some examples in
php-language (with source code of course) visit the php lab on my site.
Private homepages repositories fishing
This may, or may not bear fruits. Even using good bots, this kind of work can be
extremely tedious. I have calculated that there are at the moment more than 1000
(one thousand!) private homepages 'free' repositories à la Geocities on the web,
and that only some of them have good ad hoc search engines.
Yet the commonly upheld idea that 'serious' stuff will always necessarily be
located on own specific domains and that, conversely, only amateurish stuff can
be found on such private homepages repositories has been proved wrong often
enough. Jewels and gems, among mountains of dull crap, shine on private
homepages.
Furthermore: the inventiveness of their owners, often stimulated by the harsh
censorship applied by the 'free' providers, will let you gasp in awe: porn
images one pixel wide and one pixel high that will land 'unseen' in your caches,
mp3 files with jpg extensions, disguised as modern art, dvd descramblers source
code replicated using prime numbers, collections of tricks that -say- will allow
the use of a gsm without paying stenographed inside dull image series à la 'me
and my girlfriend Sissie visiting Dallas', and a thousand of other interesting
tricks, least but not last the javascript acrobatics used in order to nuke and
eliminate the compelled silly advertisement banners that these 'free' homepages
coerce on the zombies that use them (just to make an example the HTML 'noembed'
trick with a double html body line, but there are many more... search and you'll
find).
La va sans dire that in general you should not waste your own time perusing huge
constellations of private homepages. Ad hoc bots will allow you to grep quickly
and regularly whatever info or knowledge you are looking for. For some
bots-examples in php-language (with free source code, of course) visit the php
lab on my site.
Public counters backtracing
and other 'top 100' rankings
Many - usually small - individual sites on the web use public counters and
statistical services. These often possess their own search engines and publish
their 'top 100' rankings, that you can use to comb sites devoted to a specific
topic.
You also have other, non public counter related, 'top 100' listings. These can
at times be quite useful especially if they cover parts of the web that the main
search engines do not cover. A good example is the russian 'rambler':
for mp3... or for free soft
and web tools... http://top100.rambler.ru/top100/Software/index.shtml.ru
Web-rings searching
A webring is a set of sites of similar topic, linked in a ring so that you could
(in principle) navigate through all of them all the way back to the starting
site.
Some rings have hundreds of sites, some one or two. The population shouldn't
usually be considered when selecting promising rings, because a single site can
give you all the links and contents you need, while a random (well, not so
random) sampling of the sites of a huge ring will cover the important contents
and links (which are obviously redundant if there are so many sites).
You may start with the RingSurf Directory at
http://www.ringsurf.com/ringsearch
and check Yahoo webrings at
http://search.webring.yahoo.com/search?ringsearch
Domain-names searching
This may ('may' underlined) be of some help when combing. It is commonly made trough
netcraft. Try a search for domainnames that include
your quarry and you may find, among many 'dormient' sites, i.e.
sitenames that have already been bought but have not yet been built, some useful nuggets.
Try searching for
the term "search" for instance and you will find thousands of domainnames dedicated to
searching techniques AND to searching all kind of subjects :-)
In fact the
importance of names in Internet should never be underestimated.
The above is nice and useful in order to search for idividuals that have nothing against
sharing information and knowledge. Unfortunately the harsh reality is that many individual
are commercially depravated, and believe it is their right to hide information, plundering
the web to gather knowledge for free and trying to sell it, taking advantage of the
ignorance of the zombies.
A typical case is represented by porn-sellers. As anyone knows, there are many sites on the
web that require 'money' in order to access 'porn images'. This does not make any sense
whatsoever, if you just think at the terabites
of porn-images (truly for all tastes and perversities -) that are published everyday
on the myriad of usenet's porn newsgroups for free.
But porn-images are just an example. There are millions of 'closed' (or 'hidden') databases
on the web, where you are theoretically required to 'pay' or to adhere to some 'clan' in order to access.
Fortunately the web itself was built in order to share information, and not to hoard it. As
a consequence it is relatively easy to access ANY closed database on the web and o retrieve
any information or knowledge that has been published on Internet, no matter which precautions
have been taken to keep you out of it.
Klebing and other not kosher techniques
It is now time to examine some of the techniques you can use in order to find out those
that have searched the same nuggets you are looking for but -alas- do not want
you to share their knowledge and -in general- would rather prefer to
keep a low profile on a web they are plundering for money.
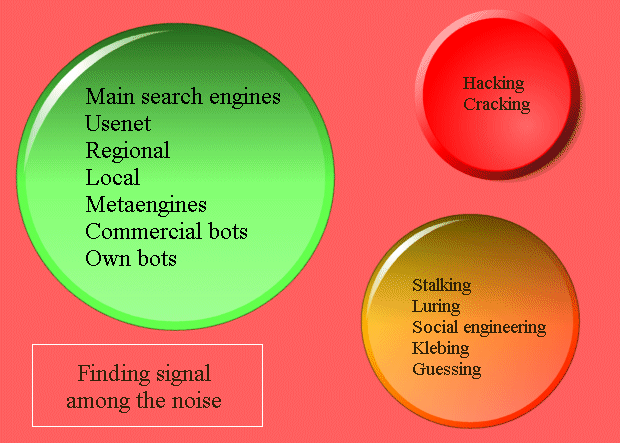
The most common approach is called 'klebing'.
This is nothing else than using the referrals inside your loggings. Often it is used together
with simple luring techniques, like
the
following: let's say you are extremely interested in a specific topic, and you have already made
your combing, and therefore you have already individuated the more useful usenet newsgroups,
private messageboards and so on, and have also already collated
a list of 'experts' on that specific topic.
Now create a page, or a site, with some of the valuable informations you have gathered, and
publicize it on said messageboards. Some of those really interested in that stuff will immediately
visit your page, thus leaving a referral in your loggings that may bring you to a 'secret'
page of theirs, to another messageboard you did not know of or to the guts of an hidden database.
This use of the referrals is in nuce klebing.
As strange as it may seem to you, very few will take
the precaution to visit first a neutral page or to kill or fake their
referrals trough proxonomitron
or any other anonymizer.
Luring
Of course simple luring
tricks can be used for all sort of purposes. Luring is for instance often used in order
to caper lusers' email accounts, getting their passwords. This requires a two-steps
luring approach. Part ONE: You open an account on -say- yahoo,
of course,
using a proxy and as always filling
the questionaries with only faked data -remember that on the web you should always lie, the more
the better, when asked for personal data-
but instead of chosing a typical johnsmith@yahoo.com account you chose something like
passwords@yahoo.com or passwordretrieval@yahoo.com or technicalservice@yahoo.com or whatever
on such lines.
Now you are the proud owner of such an account and, part TWO, you visit a messageboard or newsgroup where lusers abound, for instance a
'wannabie
hackers' messageboard,
and publish there a message similar to the following one:
"Hey, I have
discovered an incredible simple
way to get other people passwords at yahoo! Simply send to passwords@yahoo.com an email with 'retrieval'
as
subject and
with only three lines of text: your username, your password and the username of the person you
want
the password of. After a short while you will receive that password per email."
You wouldn't believe how many idiots will fall for such crap and send you their own passwords :-)
Until a few months ago you could REALLY have got an account like
passwords@yahoo.com, but due to this kind of abuse
terms like password are now been filtered for new usernames... yet this happens
only in english...
so you can still ask for
motdepasses@yahoo.com and the same trick will work, for a smaller audience, in french... or
in urdu or in whatever other
language you
chose.
The need to fight against advertisement
Advertisement has slowly pervaded every aspect of our lives. We live bombarded
with images and sounds whose only purpose is to make us react, like Pavlov's dogs or zombies,
in order to consume. We not only HAVE TO buy totally useless products: we have been
transformed in products ourselves.
Our enemies are now installing ads in
the railway tunnels... you will have a stroboscopic effect while passing by. They are going to
project ads on clouds and onto the evening sky. They have already transformed our whole life,
for profit, in an inferno of unsolecited continuous consumistic pushes. Already now you cannot
(and definitely in the future you will not) read, sleep, love, think or move around
without being bombarded by ads, all
intended to deceive you in order to push you to consume something, to buy something, to waste
your life for "their" profit.
Let's begin examining which methods we can use
to get rid of those useless ads we meet when searching. Ads in the software we
use and ads on the site we visit. If you learn just some crumbs of
the powerful reversing lore you'll be able to react.
As you'll see there
are many possible options,
and some of them -incredible but true- do actually seem to work, eheh.
A first crash-course in anti-advertisement should allow you to kill:
1.) Advertisement pushed by alien sites (HOSTS trick)
2.) Advertisement compelled by 'free' homepages providers à la Geocities (NOEMBED trick)
3.) Advertisement compelled by 'free' software you use ('procustian approach' to anner killing,
see the OPERA 5.1
example below)
1.) Advertisement pushed by alien sites (HOSTS trick)
A very simple trick is to compile a new HOSTS file
with a list of offending 'advertisement pusher' sites.
Windoze allows an effective way of filtering unwanted connections
using the hosts file (this file sits in c:\windows and
is called simply hosts, with no extension.
You can have a look and modify it using any texteditor)..
The hosts file is your 'personal DNS server': before accessing any remote
computer through a name to address lookup, windows checks the hosts
file to see if the name has been defined as an address ALREADY
in hosts (note that this is meant to
speed up the web connections you use more often: indeed if
you know for sure that a site will always have the same
IP, you can add it yourself to the hosts file and avoid the connection to the DNS server).
Through use of the hosts file we can list the names of all
servers we don't wish to contact by letting the server
name match a different address.
Typically the address used would be the 'bounce-back' localhost address 127.0.0.1.
2.) Advertisement compelled by 'free' homepages providers à la
Geocities (NOEMBED trick)
'Free' homepage providers stick their ugly compulsory advertisement code
either at the beginning or at the end of your own HTML code.
On services that stick their banner code at the very end of
your page, the simplest way to
eliminate the popups is to stick a "NOEMBED" tag after your
closing "/HTML"
This seems to work the other way round as well: for services
that stick their banner code at the beginning of
your page, create a double <<head> and <<body> line, and stick a noembed after
the first one and a <</noembed> before the second one :-)
3.) Eliminating advertisement banners in Opera 5.1.
As any searcher soon realizes, the most important 'tool of the trade' for a seeker is
the BROWSER used in order to search information and knowledge on the Web.
The best tool, by far, is at the moment Opera, a browser that will offer you many
advantages vis-à-vis the two browsersaurii Microsoft Explorer and Netscape,
last but not least the possibility to kill image loading on the fly
when visiting a site, thus
speeding up considerably any serious work on the Web.
Unfortunately the programmers of Opera decided to embed in
their great product a 'compelled advertisement': a rotating ad-banner
on the top-right corner of the browser.
This kind of hideous advertisement is getting more and more common in the current
software panorama, hence the importance of teaching anyone (and not just software
reversing experts) how to nuke it.
'Opensourcing' windows software is -as you
will now see- great fun, and will allow you to exert a considerable amount of power
onto the software you use.
In comparison with version 5.0 the programmers at Opera have now, with version 5.1.,
tried to 'mask' the 'compelled advertisement'
routine that their
product would like to impose on viewers.
If you would have had a look at the disassembled code of the older version of Opera (5.0), you
would immediately find the 'cursed' window, as I pointed out in a conference of mine at the
Ecole Polytechnique,
in Paris, some months ago:
:406D43 6A54 push 00000054
:406D45 6A40 push 00000040 ; heigth
:406D47 68D8010000 push 000001D8 ; width
:406D4C 81C128FEFFFF add ecx, FFFFFE28
:406D52 57 push edi
:406D53 51 push ecx
:406D54 56 push esi
:406D55 FF7014 push [eax+14]
:406D58 FF15A0A55500 Call dword ptr [55A5A0] ;SetWindowPos
Thus there was an extremely easy and simple way to kill the advertisements of this
very good browser. This
approach is interesting because it can easily be applied to all advertisement
infested software:
1.) You simply get height and width of the hideous banner (64*472 pixels, which
means in hexadecimal notation 0x40 height * 0x1d8 width)
2.) You disassemble your target using either wdasm 8.9 (quick and simple, but not very
powerful) or IDA 4.04 (slow and complex, but extremely powerful).
3.) You search inside the thus produced dead listing (disassembled code)
for the most 'uncommon' banner dimension (in this case the width: 1d8)
4.) You immediately land to the relevant part of the code of your target.
5.) Using any hexeditor you substitute the given width with -say- zero, thus annihilating
the banner :-)
406D47 68D8010000 push 1D8
with
406D47 6800000000 push 0
and the advertisement is no more.
Of course it would be relatively
easy to go further and just find out the routine that allows you to register
your target. The 'width' approach above is in fact
nonsense from a reversing point of view, yet it
will immediately show to those that do not know a zilch what immense
power reverse engineering can put in your hands.
In fact this
approach is just 'cosmetic': the advertisements, alas, are still loaded in
the background, and thus still
slow down your browser even if you do not see them.
As I said it would be easy (but not correct vis-à-vis the programmers
at Opera) to reverse the code in order to
avoid loading the ads from the beginning, yet I just wanted to negate
the very 'raison d'être' of the advertisement: be seen.
Moreover to kill them in this way you don't need any real reversing
skill... even your aunt could kill on these lines
almost anyone of the eyesoring advertisements that infest today's software :-)
Most of the time things will be so easy, but at times there will be some (faible) attempts
to 'hyde' the relevant code.
For instance recently (starting with the current
version 5.1 of the browser) the programmers at Opera have introduced a more 'indirect'
approach to our banner's 'magic dimensions'. Heigth and width of the advertisement rotating
banners remain
unchanged (0x40 * 0x1d8: a typical web-banner relation which is slightly superior to
1:7, in this
case 7,375).
Yet this time you wont find any 1D8 nowhere in the code.
Alas for the programmers, it is easy to find out the relevant
snippet of the code EVEN WITHOUT RELYING ON THE EXACT
DIMENSIONS.
Obviously the 1D8 width is created 'on the fly',
thus you can be sure that
the ax register is used, most probably loaded with a 'near' value to the final one,
and then something will be added to it (most probably 16, 8, 4, 2 or 1).
Searching for "mov eax, 000001D" (without
the last number) you will quickly find out that
'our' width 1d8 is now 'created' starting from a
1d4, on its turn loaded through a subroutine ad hoc.
You will easily find the following two lines of code (Opera 5.10, build 902):
:407B4B E8033D0200 call 42B853 ;call "mov eax, 1D4"
:407B50 8D7004 lea esi, dword ptr [eax+4] ;add 4 & thus get 1D8
Hence we just need to modify a line of code inside the call 0042B853 routine:
:42B855 B8D4010000 mov eax, 000001D4
with
:42B855 B801000000 mov eax, 00000001
and we'll now have an only 5 pixel wide, definitely not eye-soring...
see the small line on the right behind my shoulders? ...mini-advertisement
window... Quod erat demonstrandi :-)
(c) III Millennium by [fravia+],
all rights reserved and reversed